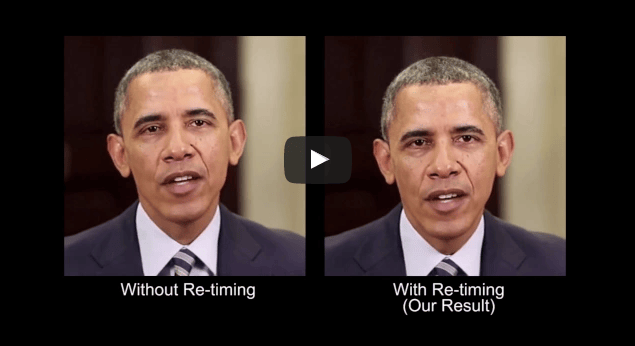
Igazából nem adtak olyasmit Barack Obama szájába, amit nem is mondott. Hanem csak olyasmit, amit nem akkor és nem úgy mondott. Elvégre komoly tudósok és nem hamisítók Supasorn Suwajanakorn és társai a Washingtoni Egyetemen. Mégis alig hiszünk a szemünknek: a szájmozgás és a szöveg tökéletesen passzol.
Azt csak feltételezhetjük, hogy a volt amerikai elnök nem sértődik meg, amiért vele kísérleteznek. Nem véletlen, hogy vele: az eljárás még kísérleti, és akkor működik igazán jól, ha nagyon sok nyersanyagot tálalnak a mesterséges intelligencia elé. Obama beszédei pedig bőséges, ráadásul szabadon hozzáférhető nyersanyagot szolgáltattak. Merthogy a trükk nem olyan egyszerűen működik, ahogyan például a vicces talkobamato.me weboldal, amely nem tesz egyebet, mint szavanként rak össze kivágott részeket a politikus beszédeiből. Az eredmény persze ugráló fej, váltakozó háttér.
A korábbi komoly tudományos munkákhoz – például a Face2Face-hez – képest fontos különbség, hogy nem meglévő videókból veszik ki a szájmozgásokat, hanem számítógépesen „mozgatják” az ajkakat. Sőt, annyira csak a hang alapján dolgoznak, hogy – más korábbi kísérletektől eltérően – a gépnek nincs is szüksége az eredeti videóra és az abban látható szájmozgásokra. További különbség, hogy az alanyokról nem kell külön e célra műtermi mozgóképeket felvenni.

University of Erlangen-Nuremberg / Max Planck Institute for Informatics / Stanford University
Suwajanakornék munkájának háttere igen bonyolult: a mesterséges intelligencia manapság egyre népszerűbb terepén, a neurális hálózatokban (azoknak is a rekurrens változatában) mozog a dolog. A gép 17 órányi Obama-beszédet (nem kevesebb mint kétmillió képkockát) elemzett. Sokat számít, hogy az elnöki beszédek felvételei HD-minőségűek, viszonylag egyformák, és Obama többnyire nagyjából a felvétel közepéről tekint a szemlélőre.
A mesterséges intelligencia a rengeteg adatból kiszámolta a hangokhoz tartozó szájmozgást, ráadásul úgy, hogy lemondott az egyes hangok (na jó, nyelvészek kedvéért: fonémák) azonosításáról, mert ez logikus ugyan, de sok hibalehetőséget rejt. Az eljárásban szerep jutott 36-dimenziós vektoroknak, amelyek leírják a szájat jelölő maszk 18 pontjának mozgását – és más olyan bonyolult dolgoknak is, amelyeket meg sem próbálunk elmagyarázni (részletek ebben a tanulmányban). Ezen az alapon képes a szoftver bármelyik Obama-felvételt úgy átalakítani, úgy betorzítani az ajkak mozgását, hogy a kép igazodjon a szöveghez.
Ez azonban nem lenne elég. Sok korábbi kísérlet – írják a kutatók – azon bukott meg, hogy a majdnem életszerű, de egy picit mégis zavaróan eltérő mimika a robotok és filmszörnyek esetében is ismert uncanny valley, a hátborzongató völgy birodalmába száműzte a beszélő fejeket. Márpedig az arc és a száj környékén különösen idegesítőek az apró eltérések.
Ezúttal tehát egy csomó más dolgot is belevettek a kísérleti módszerbe. A gép élethűen utánozza még a szavak előtti apró néma szájmozgást is. Új módszert találta ki a fogak ábrázolására (a fogakat ugyebár az ajkak időnként eltakarják, erre is figyelni kell). Megoldották, hogy amikor Obama kis szüneteket tart, akkor ne mozogjon se a feje, se a szemöldöke. A száj körüli ráncok is követik a szájmozgást. Figyeltek arra is, hogy az áll mozgása ne csak kövesse a szájét, hanem torzulásokat se okozzon az áll és a nyak környékén.
Mindez még a mesterséges intelligenciának sem megy könnyen. A 17 órányi felvétel feldolgozása körülbelül két hetet vett igénybe a hálózatba kapcsolt tíz Intel Xeon E5530 processzorral. Utána (más processzorral) egy 66 másodperces hangfelvétel „megfilmesítése” 45 percig tartott.
Meg tudták oldani, hogy az elhangzott beszédek mondatait összekevert sorrendben adják Obama szájába. Tudtak összefoglalót is készíteni: bevált rádiós módszer szerint megvágták a hangot, majd magával az elnökkel „mondatták el” saját szózatának rövidített változatát. Ami látványos különbség ahhoz képest, mint ha a videót rövidítették volna meg, az elkerülhetetlenül ugráló vagy áttűnésekkel szépítendő vágásokkal.
Mindezt jól illusztrálja a kutatók videós összefoglalója. Nem rövid, de nagyon érdekes.
A módszer egyelőre nagyon kötődik ahhoz a bőséges hang- és képmennyiséghez, amit egy emberről össze kell szedni. Az eredmény már akkor romlott egy kicsit, amikor a kutatók azzal játszottak, hogy a fiatal Obama hangjához igazítsák a mostani Obama mozgóképét. A tudósoknak erre is van tervük: lehet, hogy kellő mennyiségű adatból kidolgoznak egy általános hang- és képtárat, azt pedig elegendő lesz a mindenkori alanyokhoz igazítani. Értelemszerűen akkor az alanyoktól már kevesebb mintára lesz szükség. Még az is lehet, hogy a későbbi alanyokat az a tisztesség éri, hogy a volt amerikai elnök mintája alapján hamisítanak szavakat a szájukra. Valószínűbb azonban, hogy sok ember sok felvételéből hozák létre az általános alapot, amelyet már csak módosítani kell az egyes beszélőkhöz.
Ha máskor is tudni szeretne hasonló dolgokról, lájkolja a HVG Tech rovatának Facebook-oldalát.