

Bárkivel, bármikor előfordulhat, hogy egy papíron lévő szöveget kellene sürgősen újragépelnie. A főnökök esetében ez persze viszonylag könnyen megoldható, rábízzák ugyanis a titkárnőre. Ám már egy 5-10 oldalas dokumentum újragépelése sem könnyű feladat, lassan készül el (egy titkárnő sem feltétlenül profi gépíró), és sok esetben tele lesz elütésekkel is.
A papíron beérkező levelek, szerződések, faxok digitális formában történő tárolása is időt rabló feladat lehet, ha kézzel kell bevinni őket a gépbe.
Ha pedig nagyobb dokumentumról van szó, esetleg egy komplett iskolai jegyzetet vagy egy könyvet kell valamiért újragépelnünk, akár napokig is ücsöröghetünk felette.
Mi is az az OCR?
Nos, az OCR nem más, mint a megoldás a fenti problémákra. Egy OCR, azaz optikai karakter felismerő (Optical Character Recognition) szoftver a beszkennelt szövegből képes szerkeszthető szöveget „varázsolni”. Enélkül a szkennelt szöveg képként jelenik meg a számítógépen, amelyet elolvasni ugyan eltudunk, ám szerkeszteni nem lehet. A technológia folyamatosan fejlődik, s mára már az ilyen programok viszonylag rossz minőségű (piszkos, elkenődött, homályos) dokumentumok esetén is megbirkóznak a feladattal. Ki jobban, ki kevésbé. A kézírás felismerése például ezen a területen még mindig gyerekcipőben jár (ezt persze ne keverjük össze a különböző operációs rendszerekben megtalálható kézírásfelismeréssel, amely az érintőképernyőre rajzolt karaktereket értelmezi!).
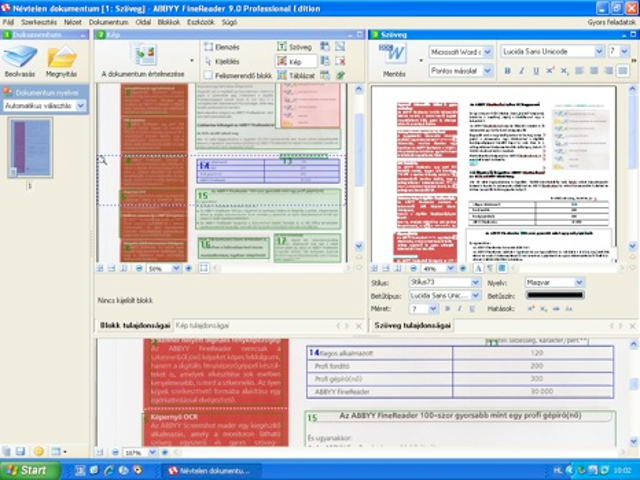
A dokumentum teljes szerkezetét megőrizhetjük
Alapesetek
A Fine Reader 9-et a rengeteg funkció és beállítási lehetőség ellenére is nagyon könnyű használni. A titok nyitja, hogy ha nem nyúlunk egyetlen beállítási opcióhoz sem, akkor is pillanatok alatt készíthetünk a szkennelt dokumentumokból szerkeszthető szöveget, amelyet azután PDF, Word, Excel, HTML, TXT stb. formátumokba menthetünk, a későbbi felhasználásnak megfelelően.
Ha tehát szerződéseket, jegyzeteket, jelentéseket szeretnénk szerkeszthető és kereshető(!) formátumban viszontlátni a képernyőn, arra az alapbeállítások is tökéletesek. Attól függően, milyen szkennerünk van, pillanatok alatt átalakíthatunk egy 10 oldalas szerződést 10 oldalas PDF vagy Word dokumentummá, és már el is helyezhetjük azt az iktató rendszerünkben, vagy küldhetjük tovább e-mailben az érintetteknek.
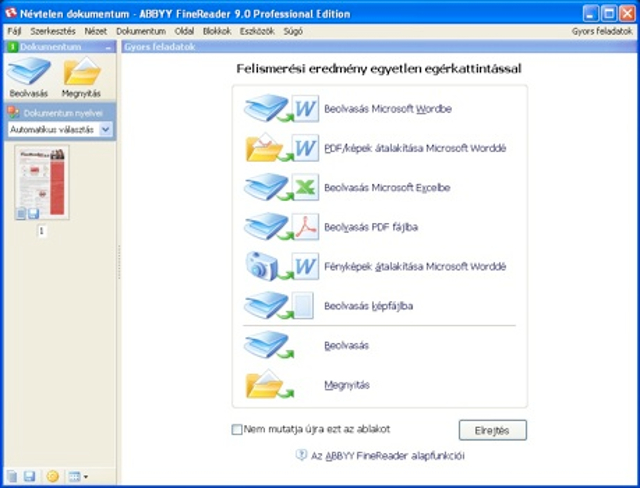
Felismerés, egyetlen kattintással
Egy nagyobb táblázatért sem kell az Excel után nyúlnunk, elegendő beszkennelni, és a FineReader gondjaira bízni, majd Excel formátumban elmenteni.
Valószínűleg ezek a leggyakoribb felhasználási területek, és ezekben a FineReader gyakorlatilag hibátlanul teljesít.
Ezeket az alapfunkciókat ráadásul az új felületen indításkor egyetlen kattintással elérjük. Ha lapadagolós szkennerünk van, egy mozdulat, és néhány perc alatt akár egy ötvenoldalas dokumentációt is elektronikus formában küldhetünk tovább, e-mailben.
Macerás esetek
Vannak persze macerásabb esetek is. Ilyen például, ha egy szkennelt oldal esetében szeretnénk megtartani annak grafikai elemeit, de egyben a szöveget is szeretnénk kereshető/szerkeszthető állapotba hozni. Prospektusok, újságcikkek esetén ez teljesen érthető elvárás lehet. A FineReader korábban is rendelkezett az ehhez szükséges eszközökkel, a 9-es verzióban azonban ezt jelentősen sikerült továbbfejleszteni. A program még a karaktertípust is igyekszik az eredetinek megfelelően választani a szerkeszthető változatban, és persze próbálja megőrizni az eredeti oldal felépítését is (képek, táblázatok, szövegblokkok stb.). Itt azonban már nem mindig működik az automatizálás, sokszor van szüksége egy kis segítségre a programnak, ám még így is jobban járunk, mintha nekünk kellene szerkeszthető formában újratördelnünk egy adott anyagot. Ez a FineReader eszközeivel – amelyeknek a segítségével mi is kijelölhetjük a szkennelt képen, hogy az adott részlet szöveg, kép vagy éppen táblázat kategóriába tartozik-e – amúgy sem különösebben megterhelő feladat. Így a program az útmutatásaink alapján állítja össze a szerkeszthető változatot.
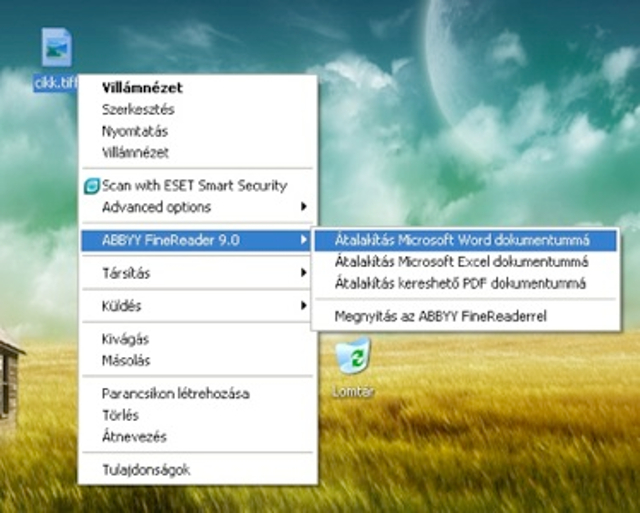
Beépül a Windows helyi menüjébe is
A tesztek során a cikkekben és prospektusokban egyaránt előszeretettel használt kiemeléseknél (keretesek) találkoztunk gondokkal, hiszen ha valóban élethű végeredményre vágyunk, akkor a keretesek színes „dobozait” is meg kellene őriznünk, bennük a szerkeszthető szöveggel. Ilyenkor a FineReader általában a szöveget részesíti előnyben, így alapértelmezésben a dobozok színes hátterét nem exportálja. A másik probléma az olyan ábrák esetében jelentkezik, amelyek több, különálló szövegrészt tartalmaznak, mivel ilyenkor a program ezeket a szövegeket hol szövegként, hol pedig grafikai elemként azonosítja.
Ám a FineReaderben még e két problémát is pillanatok alatt meg tudtuk oldani, épphogy egy kicsit kellett besegíteni a program „motorjának”, és még így is pillanatok alatt végeztünk.
Megmaradt a keretes és az illusztráció, a szövegben pedig immár kereshetünk is (exportált PDF)
Az egyetlen dolog, amire a tesztek során nem bírtuk rávenni a szoftvert, az a kézzel írt dokumentumok szövegének a feldolgozása volt, így mondjuk egy kézzel írt egyetemi jegyzet újragépelését nem ússzuk meg.
Próbálkoztunk viszont régi könyvek szkennelésével, és talán mondanunk sem kell, a program ezen a téren is tökéletesen teljesített, nem zavarták a megsárgult oldalak, a régies betűtípusok, és azt is elnézte nekünk, ha egy-egy alkalommal ferdén sikerült a szkennerbe helyezni a könyvet.
Egy teljes könyvet felismertetni így is gyorsabb vele, mint újragépelni, bár ilyen esetekben azért célszerűbb egy erre szakosodott hardvert használni, ha nem akarunk 2-300 oldalt végigszkennelni, és közben tartani egy-egy nagyobb méretű könyv szkennerből kilógó részét.
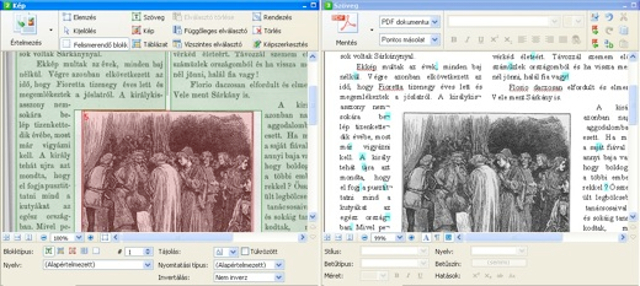
Akár régi könyvekből is készíthetünk e-bookot.
A táblázatokkal szintén elboldogult a program, s a felismerés után azokat akár Excelbe is exportálhattuk, így a szerkesztésük gyerekjáték a későbbiekben. Természetesen a dokumentumokba beszúrt táblázatok felismerése is megoldott.
Tanítsuk a szoftvert!
A FineReader új verziója 179 nyelvvel birkózik meg, ebből a 36 fő nyelv (ezek között természetesen a magyart is megtaláljuk) esetében helyesírás-ellenőrzést is végezhetünk vele, s eközben a hibásan azonosított karakterek, szavak felismerését is megtaníthatjuk a szoftvernek (bár elég ritkán téved, még az automatikus felismerés során bizonytalanként bejelölt karakterek is általában megfelelnek a valóságnak). A felismerésnél nem kell külön állítanunk a nyelvet, azt a program automatikusan beazonosítja a szöveg alapján (vegyes nyelvű szövegeknél is).
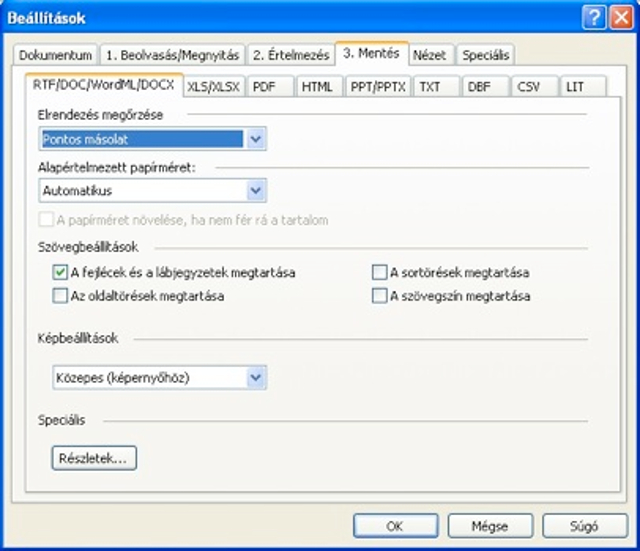
Rengeteg beállítási lehetőség a testreszabáshoz
További érdekességek
Az ABBYY még néhány extrával meg is tűzdelte az új verziót. Az egyik ilyen a Screenshot reader, amelynek a segítségével képernyőképeket készíthetünk, s az ezeken látható szövegeket ismertethetjük fel.
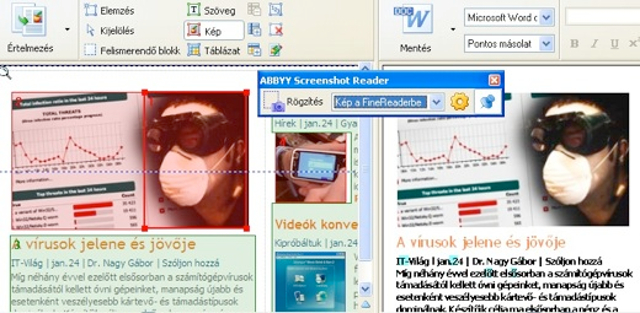
Képernyőképek készítése és felismertetése a Screenshot readerrel
Nagyszerű lehetőség a hálózati szkennerek és az MFP eszközök (multi funkciós nyomtatók) támogatása, sőt akár mappákat vagy postafiókokat is megadhatunk, amelyekben a beérkező képeket automatikusan feldolgozza a program.
Szintén hasznos – főként a nagyobb lélegzetű feladatok elvégzésénél –, hogy a munkafolyamatokat akár több PC-re is eloszthatjuk (például az egyik szkennel, a másik a felismerést, a harmadik pedig az ellenőrzést végzi).
Ahogy az manapság már szokás, a szoftvert telepítés után aktiválni kell, de a FineReader 9 esetében ezt két lépésben letudhatjuk, adatot sem kell megadnunk és a - nem kötelező - regisztrációhoz is elegendő egy név és egy e-mail cím megadása.



















