

Átfogó kutatást végeztek a jelenleg legismertebb mesterségesintelligencia-modellek teljesítményéről. A PeakX fókuszában az volt, hogy valós környezetben milyen eredményeket érnek el az egyes modellek szövegértési, matematikai és egyéb tudományterületeken.
A kutatás során a nagy nyelvi modelleknek a magyarországi kompetenciamérések során a 6., 8. és 10. osztályos diákok által kitöltendő teszteket kellett megoldaniuk. A PeakX 70 szövegértési és 70 matematikai feladatot használt az MI-modellek tesztelésére, kiegészítve történelem, természettudomány és digitális kultúra kérdésekkel. Az eszközök által adott válaszokat objektív pontozási rendszerrel értékelték, valamint több szempontot is figyelembe vettek – így a gyorsaságot, erőforrásigényt és pontosságot is.
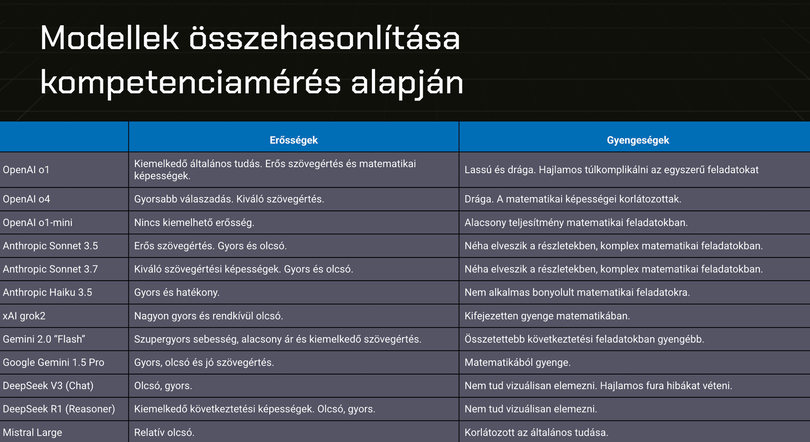
Az elemzés során megállapították, hogy a vizsgált modellek között jelentős eltérések tapasztalhatók a szövegértési és matematikai feladatok terén. Az egyes eszközök – konkrét nyelvi modellek – erősségeit és gyengeségeit ki is emelték:
- OpenAI o1: kiemelkedő általános tudással rendelkezik, erős szövegértési és matematikai képességekkel, viszont lassú és drága;
- Anthropic Sonnet 3.7: kiváló szövegértési teljesítményt mutatott, gyors és költséghatékony, azonban komplex matematikai feladatokban gyengébb;
- xAI Grok2: rendkívül gyors és olcsó, de a matematikai feladatok terén kifejezetten rosszul teljesített;
- Gemini 2.0 Flash: kiemelkedő szövegértési képességekkel bír, de az összetettebb következtetési feladatokban alulmaradt;
- Mistral Large: viszonylag olcsó, de az általános tudása korlátozottabb;
- Deepseek: olcsó és gyors, kiemelkedő következtetési képességekkel, de nem képes vizuális elemzésre és hajlamos fura hibákat véteni – írja a PeakX.
PeakX
Mint összegeznek, az érvelő (reasoning) modellek lassabbak és drágábbak, de minden kategóriában jobb eredményt értek el, mint a többi modell. Az eredmények alapján a nagy nyelvi modellek a problémamegoldó és analitikus készségeket igénylő területeken még nem képesek egyértelműen helyettesíteni az embereket, különösen a komplex matematikai készségeket igénylő feladatoknál mutatkozik meg lemaradásuk.
Azt ugyanakkor érdemes számításba venni, hogy MI-téren rendkívül erős a verseny, és szinte naponta jelennek meg új nyelvi modellek – így a fenti vizsgálat csak egy pillanatnyi állapotot tükröz.
Ha máskor is tudni szeretne hasonló dolgokról, lájkolja a HVG Tech rovatának Facebook-oldalát.













