Szeretne azonnal értesülni a legfontosabb hírekről?
Az értesítések bekapcsolásához kattintson a "Kérem" gombra!
Az értesítés funkció az alábbi böngészőkben érhető el: Chrome 61+, Firefox 57+, Safari 10.1+
Köszönjük, hogy feliratkozott!
Hoppá!
Valami hiba történt a feliratkozás során, az oldal frissítése után kérjük próbálja meg újra a fejlécben található csengő ikonnal.
Már feliratkozott!
A böngészőjében az értesítés funkció le van tiltva!
Ha értesítéseket szeretne, kérjük engedélyezze a böngésző beállításai között, majd az oldal frissítése után kérjük próbálja meg újra a fejlécben található csengő ikonnal.
[{"available":true,"c_guid":"d3a8ad25-39d3-4cf5-a6cf-449b4a198c3d","c_author":"MTI","category":"gazdasag","description":"A bányában tárolt kitermelt sót és a munkagépeket sem sikerült kimenteni. ","shortLead":"A bányában tárolt kitermelt sót és a munkagépeket sem sikerült kimenteni. ","id":"20250529_parajdi-sobanya-atszakadt-gatak-arviz-elarasztas-telegdy-barlang","image":"https://img.hvg.hu/Img/ffdb5e3a-e632-4abc-b367-3d9b3bb5573b/d3a8ad25-39d3-4cf5-a6cf-449b4a198c3d.jpg","index":0,"item":"7258d135-907c-4147-a536-287121fcf112","keywords":null,"link":"/gazdasag/20250529_parajdi-sobanya-atszakadt-gatak-arviz-elarasztas-telegdy-barlang","timestamp":"2025. május. 29. 14:47","title":"Átszakadtak az utolsó gátak is, teljesen elárasztotta a víz a parajdi sóbányát","trackingCode":"RELATED","c_isbrandchannel":false,"c_isbrandcontent":false,"c_isbrandstory":false,"c_isbrandcontentorbrandstory":false,"c_isbranded":false,"c_ishvg360article":false,"c_partnername":null,"c_partnerlogo":"00000000-0000-0000-0000-000000000000","c_partnertag":null},{"available":true,"c_guid":"8fa1acf0-8878-4d73-a47a-344262467749","c_author":"HVG","category":"gazdasag.ingatlan","description":"Részletesen elemezték, melyik kerületekbe költöztek a legtöbben, honnan mentek el sokan, és melyek a fővárosnak azok a részei, amelyek annyira népszerűek, hogy még a költözők is csak a kerületen belül vettek új lakást.","shortLead":"Részletesen elemezték, melyik kerületekbe költöztek a legtöbben, honnan mentek el sokan, és melyek a fővárosnak azok...","id":"20250529_budapest-ingatlan-koltozes-keruletek","image":"https://img.hvg.hu/Img/ffdb5e3a-e632-4abc-b367-3d9b3bb5573b/8fa1acf0-8878-4d73-a47a-344262467749.jpg","index":0,"item":"b90a0f46-15ba-4eb5-abe8-e6b5aaad0e4d","keywords":null,"link":"/ingatlan/20250529_budapest-ingatlan-koltozes-keruletek","timestamp":"2025. május. 29. 12:46","title":"A pestszentlőrinciek a leghűségesebbek a kerületükhöz, a Várból mennek el a legtöbben","trackingCode":"RELATED","c_isbrandchannel":false,"c_isbrandcontent":false,"c_isbrandstory":false,"c_isbrandcontentorbrandstory":false,"c_isbranded":false,"c_ishvg360article":false,"c_partnername":null,"c_partnerlogo":"00000000-0000-0000-0000-000000000000","c_partnertag":null},{"available":true,"c_guid":"35582785-38ce-4d7b-9d08-f01b65d9b688","c_author":"HVG","category":"tudomany","description":"Egy friss jelentés szerint a Meta a jövőben viselhető eszközöket szállíthat majd a hadseregnek, méghozzá az Oculus VR alapítójával közösen. A katonák ennek köszönhetően jobban láthatnak és hallhatnak majd a harctéren.","shortLead":"Egy friss jelentés szerint a Meta a jövőben viselhető eszközöket szállíthat majd a hadseregnek, méghozzá az Oculus VR...","id":"20250530_amerikai-hadsereg-viselheto-eszkozok-meta-oculus-palmer-lucky","image":"https://img.hvg.hu/Img/ffdb5e3a-e632-4abc-b367-3d9b3bb5573b/35582785-38ce-4d7b-9d08-f01b65d9b688.jpg","index":0,"item":"4add8155-8282-4b19-8dd3-c0b02e5157ae","keywords":null,"link":"/tudomany/20250530_amerikai-hadsereg-viselheto-eszkozok-meta-oculus-palmer-lucky","timestamp":"2025. május. 30. 12:03","title":"A hadseregnek gyárthat csodaszemüveget a Meta","trackingCode":"RELATED","c_isbrandchannel":false,"c_isbrandcontent":false,"c_isbrandstory":false,"c_isbrandcontentorbrandstory":false,"c_isbranded":false,"c_ishvg360article":false,"c_partnername":null,"c_partnerlogo":"00000000-0000-0000-0000-000000000000","c_partnertag":null},{"available":true,"c_guid":"8e9354fd-34db-4885-8cae-9082151491bd","c_author":"HVG","category":"360","description":"A walesi operaénekes a Nemzeti Filharmonikusokkal, Fischer Ádám vezényletével lép fel.","shortLead":"A walesi operaénekes a Nemzeti Filharmonikusokkal, Fischer Ádám vezényletével lép fel.","id":"20250530_Bryn-Terfel-basszbariton-Mupa-koncert-wagner-junius-8","image":"https://img.hvg.hu/Img/ffdb5e3a-e632-4abc-b367-3d9b3bb5573b/8e9354fd-34db-4885-8cae-9082151491bd.jpg","index":0,"item":"35e855c8-5f74-40de-8b1f-99d049bcf3d1","keywords":null,"link":"/360/20250530_Bryn-Terfel-basszbariton-Mupa-koncert-wagner-junius-8","timestamp":"2025. május. 30. 18:33","title":"Wagner a Müpában a robusztus basszbariton és showman, Bryn Terfel tálalásában","trackingCode":"RELATED","c_isbrandchannel":false,"c_isbrandcontent":false,"c_isbrandstory":false,"c_isbrandcontentorbrandstory":false,"c_isbranded":false,"c_ishvg360article":true,"c_partnername":null,"c_partnerlogo":"00000000-0000-0000-0000-000000000000","c_partnertag":null},{"available":true,"c_guid":"0d79c84f-c54c-442a-9b48-35d0dce01ed5","c_author":"Domány András","category":"itthon","description":"Országos tájépítészt és országos főmérnököt is kinevezett az építési és közlekedési miniszter.","shortLead":"Országos tájépítészt és országos főmérnököt is kinevezett az építési és közlekedési miniszter.","id":"20250530_Balatoni-foepiteszt-es-fotajepiteszt-nevezett-ki-Lazar-Janos","image":"https://img.hvg.hu/Img/ffdb5e3a-e632-4abc-b367-3d9b3bb5573b/0d79c84f-c54c-442a-9b48-35d0dce01ed5.jpg","index":0,"item":"d3bef135-4fce-4789-88bc-dc9710dc3e9e","keywords":null,"link":"/itthon/20250530_Balatoni-foepiteszt-es-fotajepiteszt-nevezett-ki-Lazar-Janos","timestamp":"2025. május. 30. 21:42","title":"Balatoni főépítészt és főtájépítészt nevezett ki Lázár János","trackingCode":"RELATED","c_isbrandchannel":false,"c_isbrandcontent":false,"c_isbrandstory":false,"c_isbrandcontentorbrandstory":false,"c_isbranded":false,"c_ishvg360article":false,"c_partnername":null,"c_partnerlogo":"00000000-0000-0000-0000-000000000000","c_partnertag":null},{"available":true,"c_guid":"8ea68a27-e07b-4744-8b0f-94dad73f859f","c_author":"Domány András","category":"gazdasag","description":"Közzétették a pártok a kötelező pénzügyi beszámolókat.","shortLead":"Közzétették a pártok a kötelező pénzügyi beszámolókat.","id":"20250531_Majdnem-minden-parlamenti-part-veszteseges-a-legnagyobb-30-millios-egyeni-adomanyt-a-Kutyapart-kapta-ebx","image":"https://img.hvg.hu/Img/ffdb5e3a-e632-4abc-b367-3d9b3bb5573b/8ea68a27-e07b-4744-8b0f-94dad73f859f.jpg","index":0,"item":"4f66df0c-8d91-4d1e-a4f6-cb840171e733","keywords":null,"link":"/gazdasag/20250531_Majdnem-minden-parlamenti-part-veszteseges-a-legnagyobb-30-millios-egyeni-adomanyt-a-Kutyapart-kapta-ebx","timestamp":"2025. május. 31. 09:09","title":"Majdnem minden parlamenti párt veszteséges, a legnagyobb, 30 milliós egyéni adományt a Tisza kapta","trackingCode":"RELATED","c_isbrandchannel":false,"c_isbrandcontent":false,"c_isbrandstory":false,"c_isbrandcontentorbrandstory":false,"c_isbranded":false,"c_ishvg360article":false,"c_partnername":null,"c_partnerlogo":"00000000-0000-0000-0000-000000000000","c_partnertag":null},{"available":true,"c_guid":"9b56e612-a064-4b7b-83b6-52520d4c7982","c_author":"Köves Gábor","category":"elet","description":"Mozikban régi kedvencünk 12. filmje, A föníciai séma, amely pont akkora köldöknézés, mint régi kedvencünk 11. és 10. filmje. Persze köldök és köldök között is van különbség. Wes Anderson köldöke ide vagy oda, kritikusunk elérkezettnek látta az időt a szakításra. ","shortLead":"Mozikban régi kedvencünk 12. filmje, A föníciai séma, amely pont akkora köldöknézés, mint régi kedvencünk 11. és 10...","id":"20250529_wes-andersontol-foniciai-sema-film-kritika","image":"https://img.hvg.hu/Img/ffdb5e3a-e632-4abc-b367-3d9b3bb5573b/9b56e612-a064-4b7b-83b6-52520d4c7982.jpg","index":0,"item":"56594a8c-e28d-4eb5-98c6-b1cf30f8c6d6","keywords":null,"link":"/elet/20250529_wes-andersontol-foniciai-sema-film-kritika","timestamp":"2025. május. 29. 15:01","title":"Búcsúzunk kedves barátunktól, Wes Andersontól","trackingCode":"RELATED","c_isbrandchannel":false,"c_isbrandcontent":false,"c_isbrandstory":false,"c_isbrandcontentorbrandstory":false,"c_isbranded":false,"c_ishvg360article":false,"c_partnername":null,"c_partnerlogo":"00000000-0000-0000-0000-000000000000","c_partnertag":null},{"available":true,"c_guid":"04b30712-1bb9-4e83-a122-bb41bd82b1fc","c_author":"HVG","category":"kkv","description":"Meglátszik a Szerencsejáték Zrt. 2024-es teljesítményén, hogy tavaly nyáron foci-Európa-bajnokság és olimpia is volt.","shortLead":"Meglátszik a Szerencsejáték Zrt. 2024-es teljesítményén, hogy tavaly nyáron foci-Európa-bajnokság és olimpia is volt.","id":"20250529_Szerencsejatek-Zrt-ceges-beszamolo-Nagy-Marton-100-milliard-forint-osztalek","image":"https://img.hvg.hu/Img/ffdb5e3a-e632-4abc-b367-3d9b3bb5573b/04b30712-1bb9-4e83-a122-bb41bd82b1fc.jpg","index":0,"item":"89644673-8ffe-46c6-9cd0-e3b77ac8fb17","keywords":null,"link":"/kkv/20250529_Szerencsejatek-Zrt-ceges-beszamolo-Nagy-Marton-100-milliard-forint-osztalek","timestamp":"2025. május. 29. 15:29","title":"Annyi pénzt szerencsejátékoztunk el tavaly, hogy Nagy Márton 100 milliárd forint osztalék kifizetését rendelte el","trackingCode":"RELATED","c_isbrandchannel":false,"c_isbrandcontent":false,"c_isbrandstory":false,"c_isbrandcontentorbrandstory":false,"c_isbranded":false,"c_ishvg360article":false,"c_partnername":null,"c_partnerlogo":"00000000-0000-0000-0000-000000000000","c_partnertag":null}]
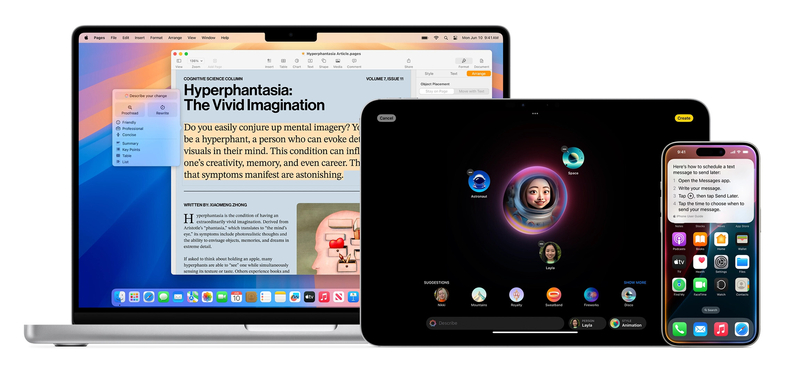
Részletesen kifejtette az Apple, hogyan tenné jobbá a különböző mesterségesintelligencia-modelljeit. Ehhez a felhasználói adatokat is használják, ami ugyan veszélytelen, de akár teljesen le is tilthatja a dolgot.
Az Apple finoman fogalmazva sem vett repülőrajtot a mesterséges intelligenciájával. Sőt, már a rajtrácson is újabb és újabb problémákkal szembesült: az Apple Intelligence szolgáltatáscsomagot 2024 júniusában mutatták be az iOS 18-cal, de végül nem lett kész az új rendszer szeptemberi rajtjára – csak október végén jelent meg.
Emiatt bőszen éri kritika a céget, és ezt már az Apple is érzékeli – a cég pedig a napokban kifejtette, hogy hogyan igyekszik javítani az MI-modelljein. Méghozzá a felhasználói adatok elemzésével.
Az Apple egy „differenciált adatvédelem” nevű módszert alkalmaz. Ezzel először szintetikus adatokat generálnak, majd ezeket összevetik a felhasználók eszközeiről származó adatokkal, hogy kiderítsék, mennyire pontosak a modellek. Ezt követően pedig elvégzik a szükséges javításokat. (A felhasználói adatokat csak akkor használja fel az Apple, ha engedélyezte az analitikai, diagnosztikai és használati adatok megosztását. Ide kattintva talál egy útmutatót arról, hogy hogyan kapcsolhatja ki ezt.)
A magyar nyelv ismerete nélkül rajtolt el az Apple Intelligence hazánkban is. Ha valaki szeretné használni, kénytelen néhány beállítást is megváltoztatni a készülékén.
A szintetikus adatok létrehozásakor a felhasználói adatok formátumát és fontosabb tulajdonságait utánozzák, de azokban nincs valós felhasználói tartalom. Például a szintetikus e-mailek esetében a reprezentatív készlet összeállításához először nagy mennyiségű szintetikus adatot hoznak létre számos témában.
Ezt követően elkészítenek egy beágyazásnak nevezett reprezentációt, melynek során megragadják valamennyi üzenet fontos dimenzióját – legyen az a témája, hosszúsága, vagy a nyelvezete. Végül ezeket a beágyazásokat elküldik néhány készülékre, melyen aktív az eszközelemzés – a mobilok pedig összevetik ezeket néhány e-mail-mintával, hogy kiderüljön, melyik a pontosabb.
Az Apple által elmondottakat összegezve a TechCrunch megjegyzi: a módszert jelenleg a Genmoji-modellek finomítására használják, de a jövőben több más területen is alkalmazni fogják – így az íráseszközök és a Visual Intelligence esetében is.
Hiába az 5,8 milliárd forint támogatás, 760 millió forint veszteséget hozott össze a Megafon. A személyi kiadások nagyot ugrottak, 877 millió forintról 1,3 milliárdra.